品牌上訊數據網關是真的嗎
數據雷達DR基于AI大模型進行分類分級:在實現數據分類分級的過程中,語義級別的數據分類分級引擎采用了基于AI大模型的先進技術。這一引擎能夠同時對數據類型進行詞法、語法和語義級別的特征提取和分析,從而建立起語義級別的高維度特征向量。通過這種方式,引擎能夠更加準確地理解和區分不同類型的數據,提高了數據分類分級的精確度和可信度。基于數據字段內容的模型訓練,保證了數據分類分級模型的可復制性:語義級別的數據分類分級引擎注重保證數據分類分級模型的可復制性,采用AI大模型進行訓練時,引擎不依賴于數據字段的名稱和注釋,即使在沒有明確的字段描述情況下也能夠達到很高的準確度。這意味著訓練后的數據分類分級模型在不同的數據環境下都能夠穩定可靠地運行,具有很高的適用性和通用性,為數據管理和安全保障提供可靠的支持和保障。 數據網關DG支持自定義敏感數據級別和類別,以滿足特定業務和合規需求。品牌上訊數據網關是真的嗎
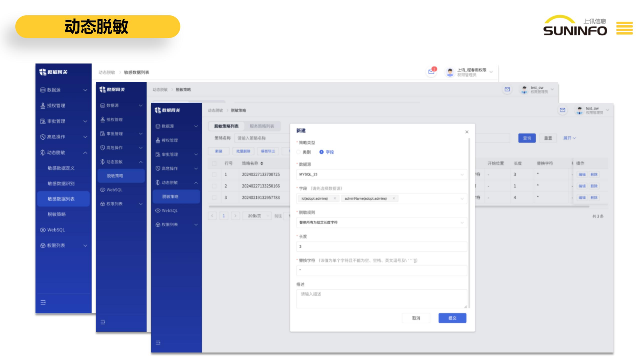
數據雷達提供了多種分類分級算法,包括AI大模型算法、正則算法、字典算法和應用算法,旨在滿足用戶不同的分類需求,提高數據分類的準確性和效率。自定義算法分組:通過自定義算法分組,用戶可以根據算法的功能、用途或者行業領域等因素進行分類,將具有相似特性或者功能的算法歸類到同一個分組下。這樣一來,用戶可以更快速地找到需要的算法,同時也可以更清晰地了解系統中各個算法的分類和屬性。分類分級算法共享:所有用戶均可在分類分級算法組織架構下共享這些算法,提升了協作效率和資源利用率。數據分類分級算法能夠為企業提供高效、準確的數據分類和分級服務,幫助企業更好地管理和保護數據資產,降低數據泄露和濫用的風險,提升數據安全性和合規性水平,增強企業對數據的控制能力,從而提升企業的運營效率和競爭力。輔助上訊數據網關信息中心數據網關DG能夠支持智能任務調度,確保任務高效執行,減少對系統資源的依賴,提升整體性能。
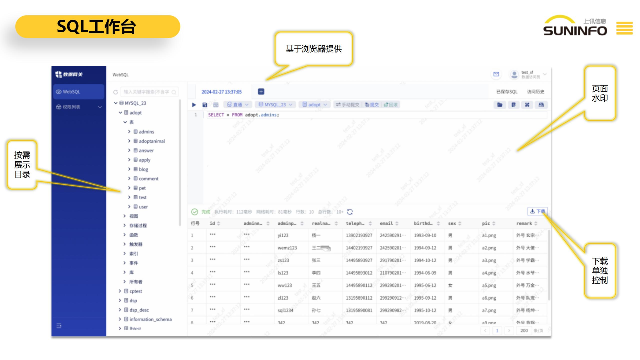
根據個人信息保護法第五十一條的規定,個人信息處理者應根據個人信息的處理目的、方式、種類以及可能存在的安全風險等,防止未經授權的訪問以及個人信息的泄露、篡改、丟失。如果企業在數據庫操作中未能合理確定個人信息處理的操作權限,或者沒有采取有效的措施來防止未經授權的訪問和個人信息的泄露、篡改、丟失,就存在嚴重的合規風險。個人信息的泄露或丟失不僅可能對用戶的權益造成損害,也可能導致企業面臨法律訴訟和信任危機。
數據網管在監控網絡流量方面扮演著重要的角色。通過對網絡流量的實時監測和分析,他們能夠了解網絡的使用情況和趨勢。流量監測可以幫助數據網管發現異常的流量模式,如突然的流量峰值或持續的高流量消耗。這可能是由于網絡攻擊、病毒傳播或某個應用程序的異常行為導致的。通過深入分析流量數據,數據網管可以確定哪些應用程序或用戶占用了大量的網絡資源,并采取相應的措施進行優化或限制。例如,如果發現某個部門在工作時間內大量下載娛樂內容,導致網絡擁堵,數據網管可以與該部門溝通,制定合理的網絡使用政策,以確保網絡資源的公平分配和有效利用。此外,流量監測還為網絡規劃和升級提供了重要的依據。根據流量的增長趨勢,數據網管可以提前規劃網絡擴容,以滿足未來業務發展的需求。
數據網關DG支持重新發現任務,同時通過歷史記錄查看已執行任務的詳細信息。
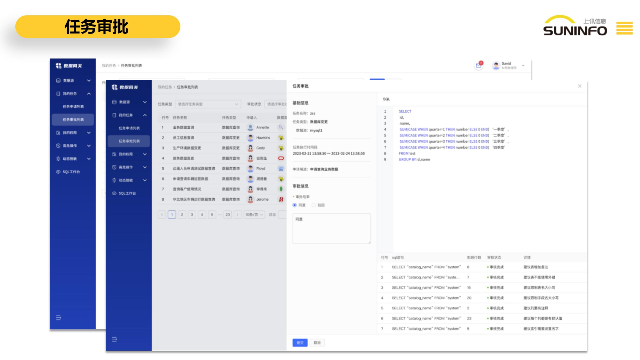
數據庫操作管理面臨著諸多挑戰,包括數據庫數量管理、數據庫變更管理、權限控制和敏感數據保護等方面。針對這些挑戰,企業需要建立數據庫管理機制和安全保障體系,提升數據管理的效率和安全性。上海上訊信息技術股份有限公司自主研發的數據網關DG通過對數據庫操作人員的細顆粒度權限管控、敏感數據動態脫敏、SQL審核、高危操作管控等,實現運維過程中的事前預防、事中管控和事后審計,為數據庫管理者提供簡單高效的數據管控解決方案,滿足內部數據安全保護需求和外部監管要求。
上訊數據網關 DG 具備強大的安全防護功能,有效抵御外部網絡攻擊,保護企業核心數據。品牌上訊數據網關是真的嗎
上訊數據網關產品支持外部應用工具通過自研訪問驅動的連接。品牌上訊數據網關是真的嗎
數據分類分級落地面臨的挑戰,傳統的數據分類分級技術無法滿足快速增長的大規模數據的需求。詞法分析的局限性導致數據分類分級的準確度較低,基于字段名稱和注釋的分類分級規則可復制性比較差,數據分類分級規則的編寫和維護需要大量人力介入。上訊數據雷達,基于AI的智能數據分類分級工具。基于AI大模型進行數據分類分級的優勢:語義級別的數據分類分級引擎,實現高精確的數據類型匹配和分類分級基于AI大模型,能夠實現同時針對數據類型在詞法、語法和語義級別的特征提取和分析,從而針對數據類型建立語義級別的高緯度特征向量,**提高了數據分類分級的準確度。品牌上訊數據網關是真的嗎
- 存儲池名稱 2025-05-08
- 敏感源端 2025-05-08
- 敏感數據處理線程 2025-05-08
- 東海證券選擇哪家的CDM 2025-05-08
- 日志校驗技術 2025-05-08
- 模糊算法 2025-05-08
- 高質量發展 2025-05-08
- 關聯關系保持 2025-05-08
- 初始的虛擬數據庫實例 2025-05-08
- 父快照名稱 2025-05-08
- 陜西有色作業票系統平臺 2025-05-13
- 適合女生的匹克球館澳洲職業匹克球運動員 2025-05-13
- 漢陽區怎樣技術服務 2025-05-13
- 貴陽餐廳的求職工資 2025-05-13
- 衢州企業網絡營銷可以不用自己學文章嗎 2025-05-13
- 換熱器壓力容器認證質檢報告 2025-05-13
- 蘇州網絡專利轉讓服務熱線 2025-05-13
- lowe's驗廠Higg驗廠lowe's驗廠Lowes勞氏驗廠輔導公司輔導機構 2025-05-13
- 深圳園林綠化工程施工哪家便宜 2025-05-13
- 無錫鐵路貨代聯系方式 2025-05-13