目標主機
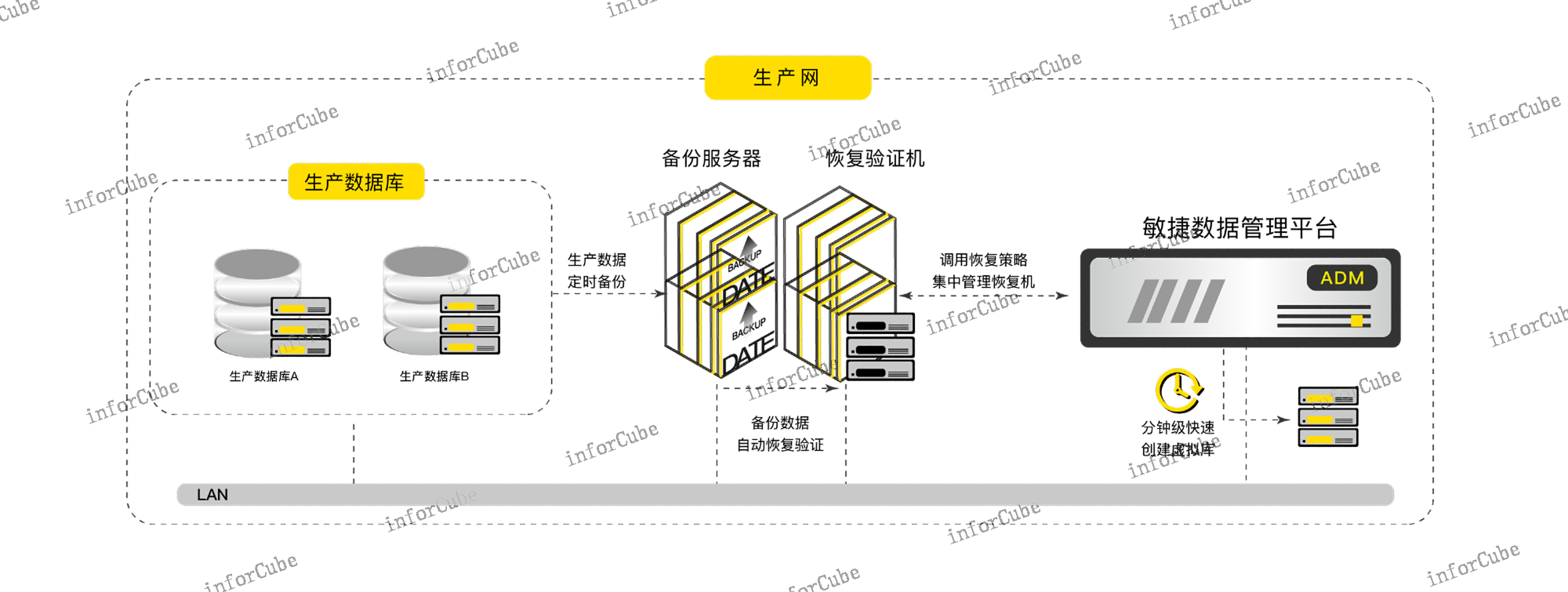
ADM產品生產數據備份恢復與異地容災對生產數據包括數據庫、文件、虛擬化平臺、容器、云服務器等進行備份,對帶庫進行數據歸檔,支持長久增量備份、數據壓縮存儲、加密傳輸、重復數據刪除等技術,采用掛載恢復方式,恢復時間為分鐘級、恢復粒度為秒級。支持數據遠程復制實現異地容災,對備份數據進行雙重保護。
ADM產品備份數據自動化恢復與有效性驗證ADM可以對接備份系統如NetBackup、CommVault、NetWorker等,檢索備份策略自動恢復備份數據和備份文件,完成驗證輸出結果。全自動化恢復驗證,可以滿足用戶對當前備份數據的可恢復性驗證、恢復后的完整性驗證,覆蓋備份數據和備份文件的恢復,支持虛擬掛載恢復和物理恢復雙重方式。 上訊敏捷數據管理平臺ADM產品的合規性體現在通過數據申請審批流程使用數據,嚴格控制數據外流。目標主機
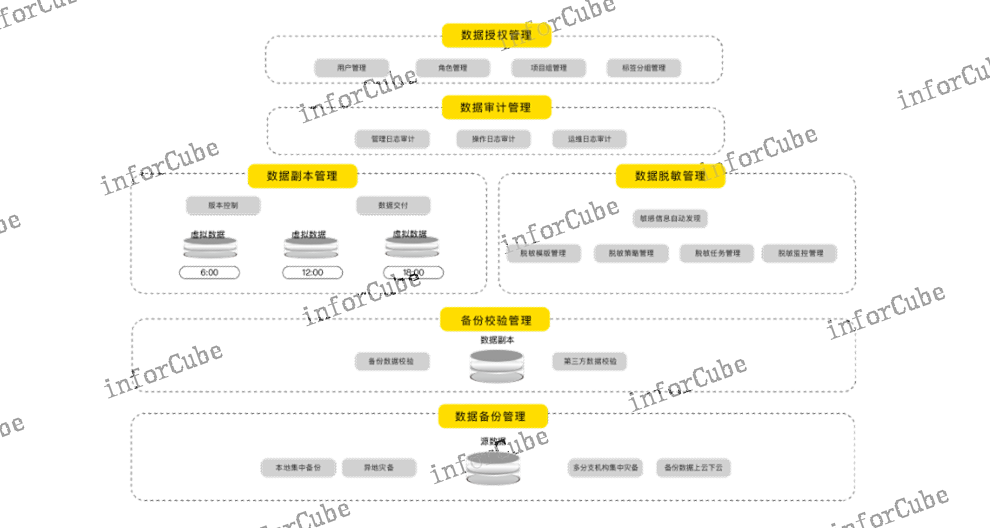
數據副本管理是ADM功能模塊之一,可單獨作為企業級副本數據管理(CDM)產品。為應對當前復雜的IT環境,ADM提出集云、物理、虛擬為一體的,面向結構化數據庫、非結構化數據、虛擬化和云平臺的***數據副本分發與交付管理解決方案。主要通過數據副本管理的核心專利技術——數據庫虛擬化技術對源數據進行CDM原格式獲取生成黃金副本、存儲黃金副本作為基準數據、虛擬化為多個副本掛載恢復,**終達到快速交付副本數據、靈活管理副本數據版本、集中管理副本數據存儲與流轉的目標,是主要面向企業數據運維、軟件開發測試部門解決自動化閉環取數供數、測試數據快速交付等典型應用場景的問題。周期跨域上訊ADM產品的高效性體現在數據從上游生產環境到下游使用環境通過虛擬副本創建實現分鐘級交付。
上訊敏捷數據管理平臺(ADM)支持重復數據刪除技術,在典型的重復數據刪除技術中,根據不同的數據備份場景選擇適合的重刪策略與粒度方案。在確定重刪策略與粒度后,會根據輸入側不同粒度(卷級、文件級、塊級)的數據采取不同的數據切分策略,并依據任務級與全局指紋庫提供自適應源端的全局重刪算法與策略,當前支持源端塊級、文件級重刪和并行重刪技術。源端重刪是采用基于內容的可變長數據切分算法,通過對數據塊進行哈希算法的標記,即指紋(Fingerprint),在指紋庫中尋找相同的指紋。如果存在相同指紋,則表示已保存了相同的數據塊,ADM則不再保存此數據塊,而是引用已存在的數據塊,從而節省更多的備份空間。該算法還可以智能識別已修改的數據和未修改的數據,從而避免因修改數據位移而導致的未修改數據切分到新數據塊中的問題,較大限度地提升重刪性能和重刪率,為避免數據備份過程中冗余網絡傳輸與存儲開銷,在源端設置粗粒度前置數據校驗可以明顯縮小備份傳輸過程中的數據冗余,目的在于不備份任意一個冗余數據。
上訊敏捷數據管理平臺(ADM)數據復制容災模塊主要包括數據遠程復制、數據異地容災兩大功能點,是基于ADM系統底層的數據塊增量復制功能,全量復制傳輸,后續增量復制與全量快照合成傳輸,實現本地和異地均可以同時提供虛擬庫對外訪問。主要解決數據全生命周期管理中數據傳輸流轉的安全問題,基于數據備份任務和虛擬副本任務,將源數據和副本數據存儲到本地ADM的存儲池中,在本地ADM和遠端ADM之間創建遠程復制鏈路,根據遠程復制策略,將本地存儲池中的數據同步到遠端ADM存儲池中,從而為副本數據提供從上游到下游的安全傳輸路徑。上訊ADM產品的可管理性體現在數據從上游到下游獲取、傳輸、流轉的集中式管理,同時可進行版本管理。
在國家大力發展信創的背景下,實現國產化軟硬件部署已成為企業的**訴求,其中逐步建立覆蓋國產化數據庫、操作系統、虛擬化平臺的國產化數據保護體系,實現備份數據自動化恢復驗證成為當前數據保護系統的迫切需求。同時,以金融和運營商行業為例,其開發測試部門需要頻發測試驗證,對數據使用頻率較高,因此形成了大量不同版本的測試數據,這部分數據體量龐大,動輒幾百GB甚至幾十TB,管理難度較大。國家日趨重視對數據隱私的安全管控,數據脫敏成為企業數據安全治理的重要方向。上訊信息敏捷數據管理平臺ADM是創新型數據備份管理解決方案。數據庫敏感數據處理
上訊ADM產品采用副本數據管理CDM面向數據全生命周期進行數據安全管理。目標主機
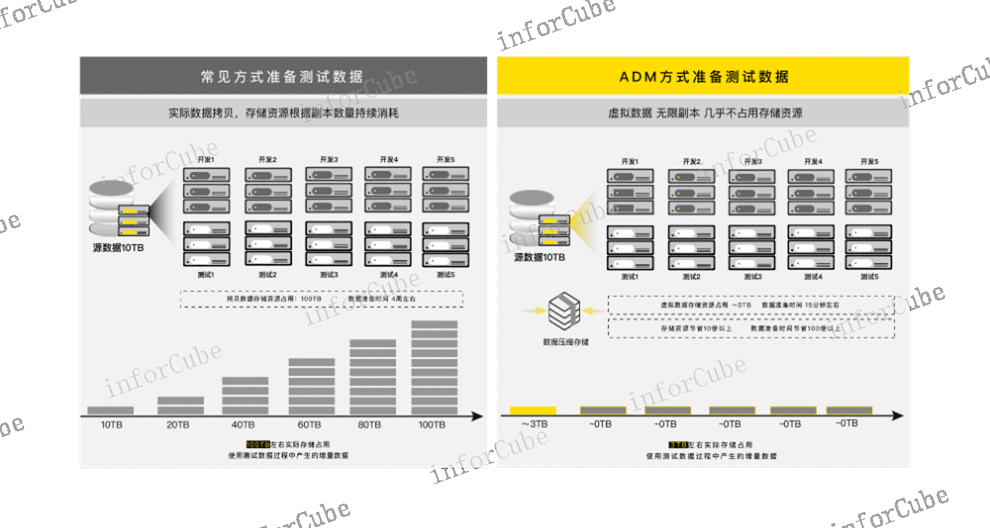
功能節點統一管理,支持彈性擴展ADM采用多節點高可用部署架構,保障數據服務高可用,并消除單節點故障導致的業務不可用問題,確保數據服務連續性。采用Scale-out架構,根據業務發展規模,按需擴展集群節點,無需停止服務,靈活滿足業務需求。同時,ADM支持存儲池容量的彈性擴充,滿足不斷增長的數據存儲需求。(2)數據存儲成本倍數級節約,提升數據存儲環節的效能首先,數據備份面臨存儲成本高的問題,ADM采用內置高效的壓縮存儲池存放數據,壓縮比約為3:1,存儲即壓縮,***降低了備份數據的存儲成本;其次,通過ADM的數據庫虛擬化技術,一份基礎數據即可快速拉起多份虛擬數據庫,由于虛擬數據庫90%的數據均與原始數據相同,因此拉起時幾乎不占用額外的物理存儲空間,*對新增的寫操作計入容量占用,因此,隨著數據分發使用的場景和頻率增加,虛擬庫的數量越來越多,而存儲成本將會呈倍數級節約,例如針對同一份數據創建N個虛擬庫,傳統方法需要N倍的存儲空間占用,而通過ADM只需要占用近乎0TB的存儲空間,**節約了數據存儲環節的資源和成本。目標主機
- 存儲池名稱 2025-05-16
- 文件備份策略 2025-05-16
- 金融行業示范性案例 2025-05-16
- 數據準備和交付 2025-05-16
- NetBackup安裝路徑 2025-05-16
- 工商銀行對CDM的應用場景 2025-05-16
- 敏感數據定義 2025-05-16
- 敏感類型自定義 2025-05-16
- 高效使用 2025-05-16
- 金融數據 2025-05-16
- 西藏網絡AI人工智能大數據云計算產品 2025-05-18
- 江西城市供水管道檢測報價 2025-05-18
- 連云港通用mes管理 2025-05-18
- 中國香港零碳酒店 2025-05-18
- 溧水區法醫臨床鑒定常見問題 2025-05-18
- 深圳http代理認證 2025-05-18
- 保定什么企業注冊公司推薦 2025-05-18
- 電子人力資源報價 2025-05-18
- 本地廣告設計價位 2025-05-18
- 富民廣告報價 2025-05-18