數字圖書館文獻知識發現簡介
文獻數據庫列表明細:當前數據源檢索下的站點明細(如:數據源為一個數據庫,則在站點明細中只出現該數據可。) 在站點明細中可以,可以查看各個具體文獻數據庫的瀏覽,閱讀,下載,以及流量情況,支持對應排序。用戶列表明細,可以查看用戶具體的訪問情況,例如:當前選擇的數據源為CNKI這個數據庫。則在用戶列表中為所有用戶訪問CNKI的明細,包含,閱讀,下載,瀏覽,站點數以及流量。如選擇統計數據源為部門,則用戶站點數就為該用戶一共訪問的數據庫個數。 ?查詢文獻知識需要付費嗎?數字圖書館文獻知識發現簡介
作者是誰?他們還出版了什么?這篇論文是他們曾經研究內容的工作延伸嗎?文章的目的是什么?你認可他的觀點嗎?他的這篇文章研究調查、評論或分析了什么?這個課題有意義嗎?為什么?作者采用了哪些方法、理論或分析框架?這些是適當或合理的嗎?得出了哪些結論?這些證據是否合理?研究設計有什么限制嗎?調查教過是否確鑿適用于你的研究?上述的這些問題可以幫助你更好的對文獻進行分析或闡述,不過,它只是一個起點,你可以試著在閱讀時提出并添加自己的問題或想法。當你開始試圖評估文章、研究和方法時,了解誰是你研究領域中的會對你很有幫助。你可以通過搜索,找到哪些文章或作者被引用的頻繁,這被稱為「citationsearch」。通過諸如WebofScienceCitationIndex和SCOPUS之類的數據庫,它們索引了science,socialscience和arts&humanities受到高度重視的學術期刊,能夠更容易的追蹤誰引用了某個作者的作品,或者找出哪些是常被引用的文章。安徽文獻知識發現是什么文獻的概念和意義是什么?
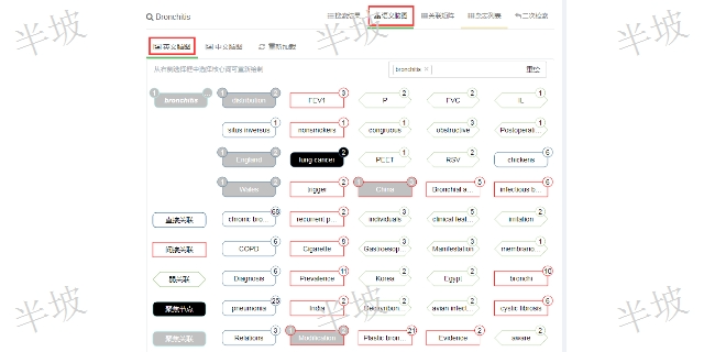
語義關聯矩陣:首先,語義腦圖從當前所截獲的文獻中提取若干概念性語詞。例如讀者搜索“硫化氫”,系統會從當前搜索結果文獻的文本中實時提煉出脫硫劑、地下水、氣相色譜法、缺血、自噬、氨氮、污水處理廠等若干文本語詞。之后,語義腦圖以一個5列12行的關聯矩陣來表達概念語詞之間的語義關系:將讀者搜索詞排列在矩陣的左側一列作為起始中心節點,后續右側各列選詞由左鄰側列的概念語詞關聯推導產生,同一列內概念語詞按語義權重降序排列。然后,各個概念語詞依據和中心節點(搜索詞)的語義關聯度,在語義腦圖中表現為:中心節點(搜索詞),直接關聯節點(紅色邊框)、間接關聯節點(長方型邊框)、弱關聯節點(菱形邊框)等三個層級的語義關系。也就是說,將傳統搜索引擎按年代(或按相關度)降序排列搜索結果的單一維度模式,提升為一個圍繞著讀者搜索詞一次性展開近50個概念語詞的具備語詞間層級關聯和權重有序的二維語義關聯矩陣(發明專項權利,PCT國際專項權利CN2018/081327,美國專項權利:16314840)。任意概念節點的右上數字角標(表示相關文獻數)可以迅速定位鏈接到當前細分概念的相關文獻。
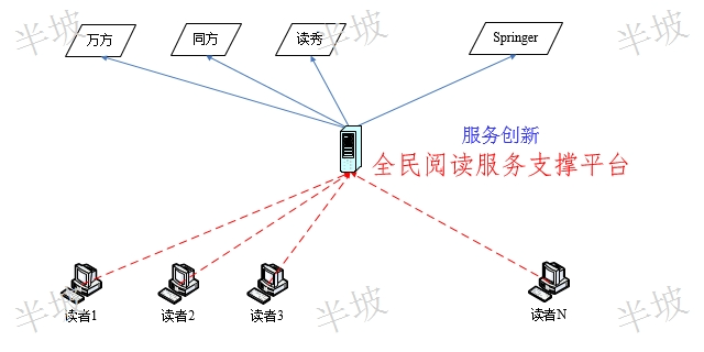
隨著圖書館數字文獻資源的規模越來越大;數據庫品種數量越來越多,;讀者服務的手段(遠程、移動、跨庫搜索等)也越來越多樣化。但是,如何能使圖書館清晰了解讀者的閱讀行為,優化現有數字文獻館藏,讓有限的數字資源采購資金發揮更大的讀者服務效益?其中,哪些部門、哪些讀者在使用?使用哪些文獻數據庫?數字文獻利用統計在圖書館工作中,越發顯得越為重要。然而,數字圖書館目前服務現狀是:圖書館統一采購數字文獻資源,圖書館的讀者各自分別訪問一個個的數字文獻資源數據庫。現有的文獻數據庫-讀者文獻利用模式在示例的網絡拓撲中,我們很難確定圖書館所處的位置。由此可見,隨著讀者數字文獻需求不斷增長、文獻數據商蓬勃發展,圖書館的服務功能卻正在逐步被邊緣化。在上述文獻數據庫-讀者文獻利用模式中,常見的傳統計量評價方法包括:圖書館資源首頁數據庫進入次數統計、文獻數據庫原廠商各自提供的訪問量/下載量報表等。但實際情況是:這些數據很難真實反映讀者文獻數據庫的實際利用情況。依據國際定義文獻知識乃是一切情報的載體。
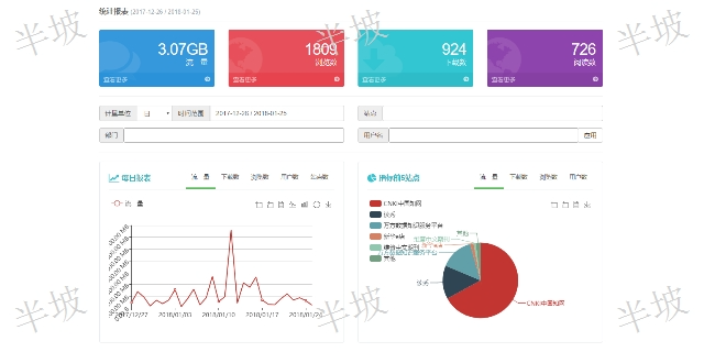
基于中樞網關模式的文獻利用統計將能夠提供針對圖書館所有文獻數據庫的、針對各個部門的、針對單個期刊品種的、針對單個讀者等等,以每篇閱讀文獻為基礎單位的文獻利用統計分析。能夠真實反映讀者和文獻數據庫利用情況,為圖書館讀者服務工作和為圖書館資源采購決策(包括試用數據庫)提供精細的科學依據。統計分析模塊中主要分為數據庫統計,用戶統計,部門統計。其中每種統計,都會對其流量,瀏覽數,下載數,閱讀數進行詳細統計。并且每種統計支持年月,日等相關條件限定。選擇對應的數據條件可以是單個條件,組合條件。例如:我們可以選擇一個具體的數據庫,,讀者,部門進行統計。也可以選擇對應部門下這個站點的使用情況,以及當前讀者訪問這個站點的情況。(本實例中,默認是統計近30天該數據庫使用情況)。(這里我們選擇CNKI數據庫)。上海半坡是專門為圖書館提供文獻知識服務的公司.數字圖書館文獻知識發現簡介
通常在什么場景用到文獻知識?數字圖書館文獻知識發現簡介
文本語義腦圖的算法基礎:1、以讀者當前搜索詞作為啟始節點(DI一起始列),后續(右側)的第n列數據是由前n-1列的節點元素在文獻搜索結果中推導而得(概念之間同句共現關系)。2、單一列向量空間內,由上至下所有節點之間依據該文本概念詞的語義權重和文獻時序權重,反映列內語義節點的先后有序特性。3、任意概念節點右上數字角標表示其在搜索結果中的文獻數。點擊該文獻數則顯示相應的文獻指引(基于文本概念的細分聚類)。4、選擇語義腦圖中任意節點(x)作為興趣點(聚焦節點),可以進一步推導出該節點的所有直接關聯節點(y)。5、興趣聚焦操作時(x-y)左上角標指引聚焦關聯文獻(隱性知識發現)。6、任意節點可以選作為新的起始重心節點(a),重構一幅全新的語義腦圖(擴散思維)。文本語義腦圖能夠揭示一站式跨庫搜索結果內文本信息之間多層次的語義網絡關系并迅速定位檢索命中文獻。數字圖書館文獻知識發現簡介
上海半坡網絡技術有限公司主營品牌有上海半坡,數字圖書館增值服務,致匯,知識鏈發現,發展規模團隊不斷壯大,該公司服務型的公司。上海半坡是一家有限責任公司企業,一直“以人為本,服務于社會”的經營理念;“誠守信譽,持續發展”的質量方針。公司擁有專業的技術團隊,具有計算機軟件,網絡信息,技術咨詢,技術服務等多項業務。上海半坡順應時代發展和市場需求,通過**技術,力圖保證高規格高質量的計算機軟件,網絡信息,技術咨詢,技術服務。
- 信息智慧導讀概況 2025-05-05
- 上海智慧導讀用戶體驗 2025-05-05
- 參考智慧導讀用戶體驗 2025-05-05
- 一站式智慧導讀特點 2025-05-05
- 安徽智慧導讀哪家好 2025-05-04
- 四川智慧導讀案例 2025-05-04
- 智能化智慧導讀發現 2025-05-04
- 綜合智慧導讀費用 2025-05-04
- 安徽智慧導讀費用 2025-05-04
- 上海智慧導讀服務 2025-05-04
- 流量模型 2025-05-07
- 海南企業3D打印全國安裝 2025-05-07
- 江門房屋水電安裝工程價格 2025-05-07
- 張家港信息化展覽展示便捷 2025-05-07
- 東莞潤數工廠生產數字化管理軟件多少錢 2025-05-07
- 上海噴砂不銹鋼酸洗鈍化公司 2025-05-07
- 連云港工商網站優化報價方案 2025-05-07
- 河南連鎖店3D打印物流 2025-05-07
- 貴陽火鍋店的求職在什么軟件上找 2025-05-07
- 高新區專業性硬件哪個好 2025-05-07